The Feldera Blog
An unbounded stream of technical articles from the Feldera team
 Agents
AgentsAgents Aren’t Coworkers, Embed Them in Your Software
Agents do not need more human-like conversation. They need software that makes conversation unnecessary. Give them the right interfaces and they stop acting like noisy copilots and start acting like infrastructure.
 Incremental Compute
Incremental ComputeMaking samply profiles even more useful
Feldera cut one customer’s backfill time from 20 hours to 4 by getting serious about profiling. In this post, we share how we made samply profiles significantly more useful by postprocessing their output to add application-level markers — no changes to samply required.
 Incremental compute
Incremental computeTurns out we didn’t need that second index
Building an incremental compute engine means constantly asking whether the runtime is doing more work than it needs to. This time the answer was yes, and the fix made every pipeline that shares a join source cheaper to run.
 Incremental compute
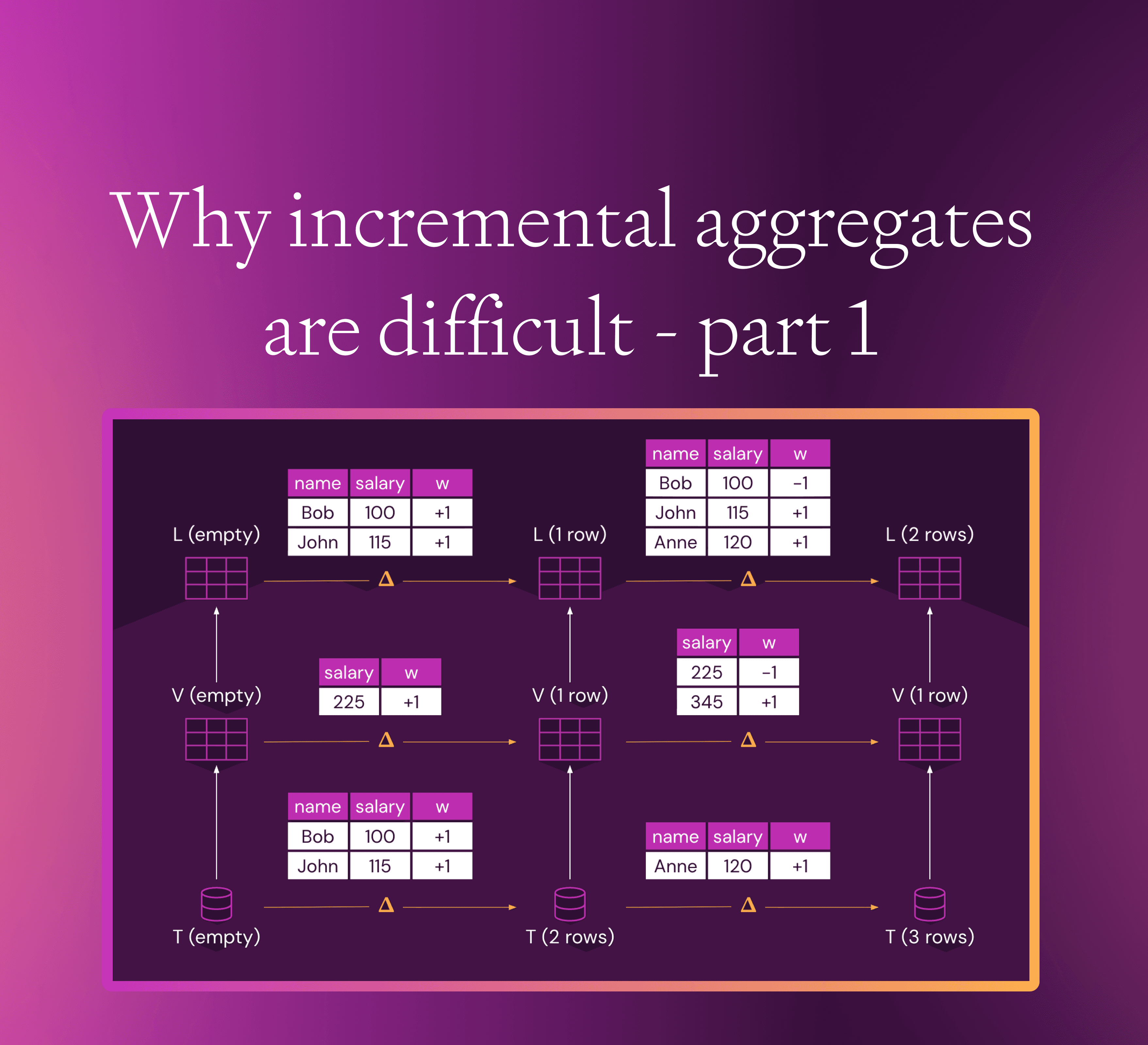
Incremental computeWhy incremental aggregates are difficult - part 1
Many traditional query engines may be able to handle only some kinds of queries, or only some kinds of input updates incrementally, reverting to full recomputation for unsupported operations. Feldera uniformly handles insertions and deletions and stacked views using arbitrary monotone and non-monotone queries.
 Rust
RustNobody ever got fired for using a struct
Rust structs are usually the obvious way to represent data. But when you serialize wide SQL tables with hundreds of nullable columns, that “obvious” layout can quietly double your storage cost. Fixing it turns out to be a surprisingly simple trick.
 Incremental compute
Incremental computeCan your incremental compute engine do this?
Handle 217 join, 27 aggregations, and 287 linear operators on a single 16-core machine using 15GB RAM at steady state. Here’s the proof.
 Product announcement
Product announcementIntroducing Feldera Health
Introducing Feldera Health: a lightweight dashboard that shows your infrastructure status without Kubernetes access. Get quick answers when pipelines fail.
 Incremental compute
Incremental computeFeldera in 2025: Building the Future of Incremental Compute
Feldera broke this 50-year barrier with incremental computation. A better way to create sophisticated analytics at the speed your data actually changes: real-time.
 Product announcement
Product announcementIntroducing Feldera’s Visual Profiler
We built a browser-based visualizer to dig into a Feldera pipeline’s performance metrics. This tool can help users troubleshoot performance problems and diagnose bottlenecks.