Feldera performance on Nexmark versus Flink
This blog post presents a snapshot of Feldera's performance against Flink on Nexmark, a benchmark often used to compare the performance of streaming engines. We implement Nexmark queries in SQL for Feldera, whereas Flink is using its Java API.
Summary of results: On Nexmark, Feldera is up to 6.2× faster than Flink and, in most cases, uses less memory and CPU time. It's important to note that Feldera offers these improvements while also providing strong consistency guarantees out-of-the-box, which Flink SQL does not. Feldera also supports arbitrarily complex SQL and is a much more powerful engine under the covers than Flink.
Nexmark consists of queries numbered q0 through q22. We benchmarked the queries that the Flink and Feldera implementations have in common. We omitted q6 because there was no Flink implementation, and q10 because we could not make Flink's implementation for it work. We omitted q11 and q21 because Feldera does not yet support session windows and user-defined functions (work in progress).
We ran both the Flink and Feldera implementations on the same machine, which has a 64-core, 128-thread Threadripper 3990X CPU and 256 GB RAM, with Fedora Core 40 as the operating system. We present results for 100 million Nexmark events (input records), which is a moderate number.
We ran Feldera as a single process configured with 16 worker threads and otherwise with default settings. We ran Feldera both with storage disabled, where Feldera keeps all state in RAM, and with storage enabled, where Feldera flushes state to SSD as it gets large. Enabling storage allows Feldera to work with more state with less memory use, at some cost in throughput. We blogged about storage in Feldera previously.
We configured the Flink implementation of Nexmark with the settings recommended by the upstream project, running 8 Flink task manager containers, each allocated 2 cores, and one Flink job manager container. We tried adjusting Flink and Nexmark settings, but none of these changes improved Flink performance in a significant and reproducible way.
Feldera and Flink support reading input from multiple kinds of data sources. For these measurements, we configured both of them to use their own integrated Nexmark event generators, rather than pulling them from Kafka or HTTP or another source. This eliminated network service performance and configuration as a possible source of variability.
Throughput
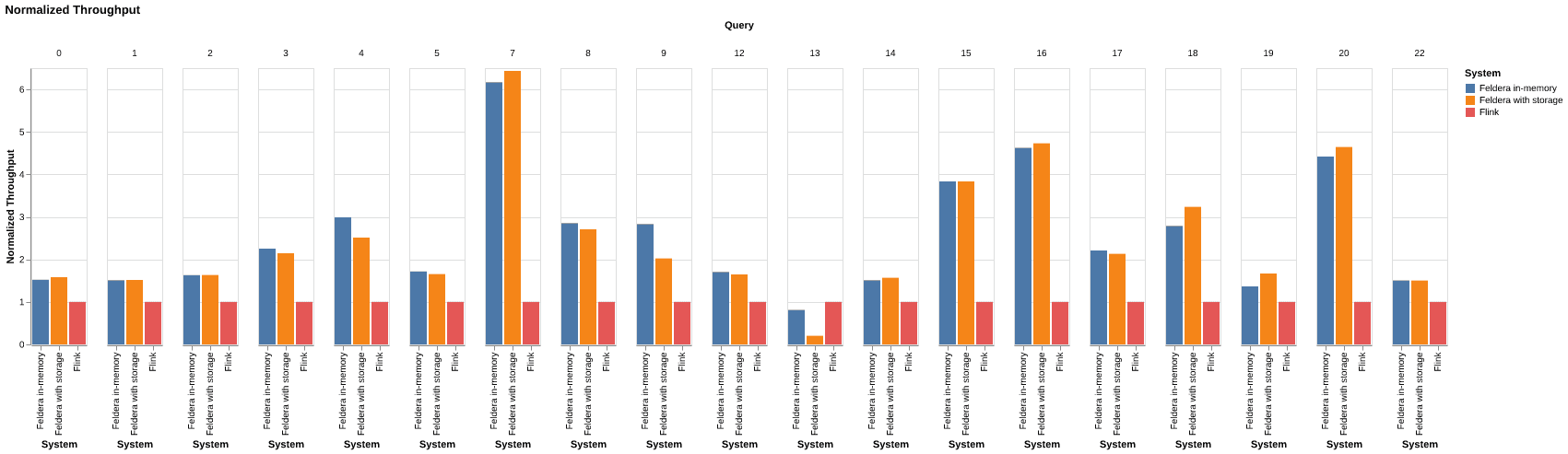
The following graph compares the throughput of Flink and Feldera for the Nexmark queries. Throughput is measured in events processed per second, and larger numbers are better.

The following graph shows throughput relative to Flink, so that the Flink bars are a constant length:

The speedup for in-memory Feldera versus Flink is up to 6.2×, with a geometric mean of 2.2×:
- As queries get more complicated, Feldera's advantage over Flink grows by a much larger factor. For example,
q7is 6.2× faster in Feldera vs. Flink, andq16andq20are about 4.5× faster. q13is an outlier that performs slightly slower in Feldera than Flink; with storage enabled, it is slower than Flink. Withq13excluded, every remaining query runs at least 1.4× faster in Feldera (with or without storage). We are investigating Feldera's performance withq13.- Storage generally has a small impact on throughput in Feldera, except for
q13, where it has a ~4× penalty. q0and other very simple queries perform about 1.5× faster with
Feldera than Flink.
Memory Usage
We also measured the peak amount of memory use, as reported as the operating system RSS (resident set size), for the Flink or Feldera processes. For Feldera, this is a single process; for Flink, it is the sum of the RSS in the 8 task manager containers. We did not include the control plane in either case (in Feldera, the pipeline manager; in Flink, the job manager).
Memory is measured in GiB (2³⁰ bytes). Smaller numbers are better.

As before, we also show memory usage relative to Flink:

Feldera uses between 0.03× and 2.6× as much memory of Flink, with a
geometric mean of 0.24×:
q0and several other queries use 2 GiB or less memory with
Feldera, but 17+ GiB with Flink. These queries do not require
Feldera to store any state, or only minimal state, so it does not
allocate much memory. Flink runs under the Java Virtual Machine,
which might cause it to allocate a high minimum amount of memory.
We previously discussed this property of some of these queries as groups 2 and 3 in Meet the Feldera storage engine: Results. Since then we have implemented more queries and improved the performance of others, so the discussion there applies more widely.- Most queries use less memory in Feldera than in Flink.
q9andq13use substantially more, andq18andq19use somewhat more, and in each case storage helps.
CPU Usage
Finally, we measured and graphed the total CPU usage across Feldera's process and Flink's task manager processes. As opposed to the fixed number of processes and threads, this is the amount of CPU time actually consumed for either system to process a query.
CPU usage is measured in CPU-seconds. Smaller numbers are better.

The corresponding relative graph is:

Feldera uses between 0.2× and 2.3× as much CPU time as Flink, with a geometric mean of 0.8×:
q4,q7,q9, andq20use the highest absolute amounts of CPU time with Flink. For these, Feldera uses less than 50% as much CPU time, even with storage enabled in most cases.q0,q1,q2,q14, andq22use about 20% to 60% more CPU time than Flink, but the absolute amount of CPU time they use is among the lowest in the set of queries, and these queries also complete about 1.5× faster than Flink for the same amount of data.q13uses over 2× as much CPU time with Feldera than Flink, although the absolute amount it uses is not high. Enabling storage increases CPU use to 7× Flink. We are investigating the reasons.- Enabling storage generally has a small impact on CPU use, except for
q13.
Conclusions
This blog post presents a snapshot of Feldera's performance. Feldera is up to 6.2× faster than Flink and, in most cases, uses less memory and CPU time. At the same time, Feldera provides strong consistency guarantees out-of-the-box, which Flink SQL does not, and supports arbitrarily complex SQL. We're constantly working to make Feldera run faster with less memory and CPU, so you can expect to see even better numbers over time.


Other articles you may like

Database computations on Z-sets
How can Z-sets be used to implement database computations

Implementing Batch Processes with Feldera
Feldera turns time-consuming database batch jobs into fast incremental updates.

Feldera: three tools for the price of one
Feldera is not just a database engine. Feldera SQL is in some respects substantially more powerful than standard SQL, enabling new use cases.