Storage has shipped!
With our recent release, we shipped the "storage" feature for Feldera, which enables the query engine to easily handle datasets larger than memory.
Let's look at an example to see what that means for for Feldera users. Consider the Nexmark benchmark, which is commonly used to measure the performance of streaming systems. It simulates an online auction system with tables that represent auctions, bidders, and bids. Let's run Nexmark query q19, which selects the top 10 bids on each auction. It uses only the bid table and in Feldera it can be defined in SQL this way, given the bid table definition:
CREATE VIEW q19 AS
SELECT * FROM
(SELECT *, ROW_NUMBER() OVER (PARTITION BY auction ORDER BY price DESC) AS rank_number FROM bid)
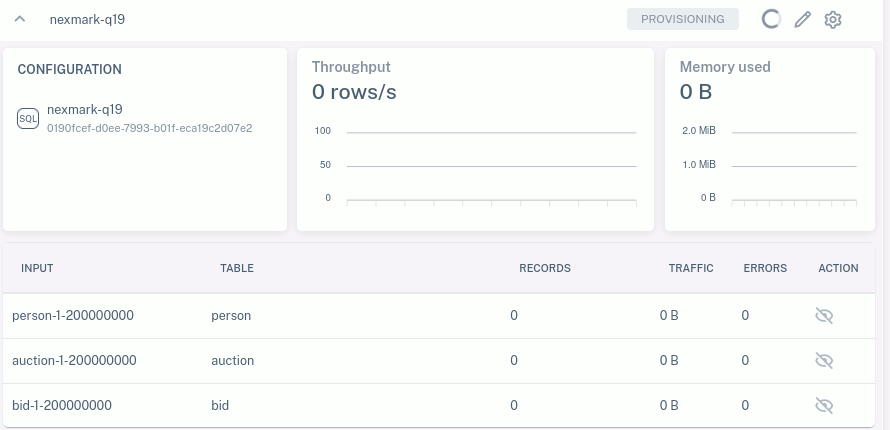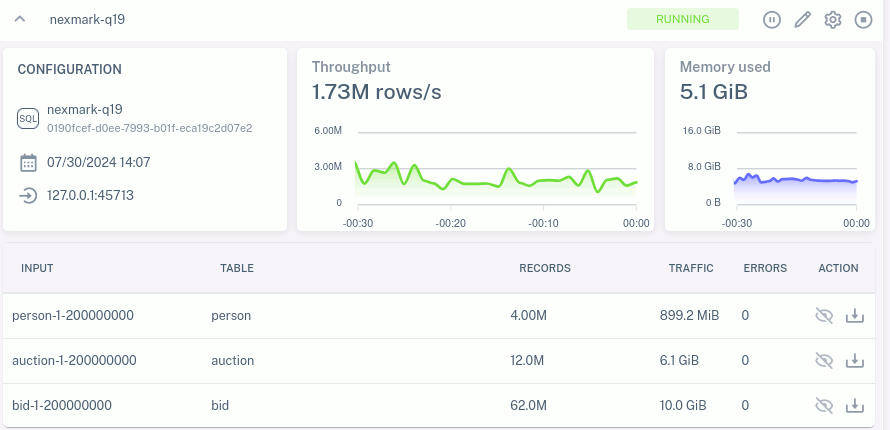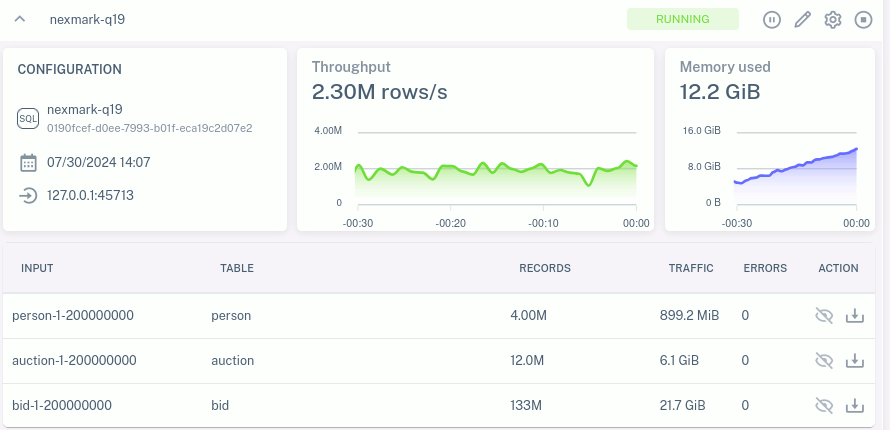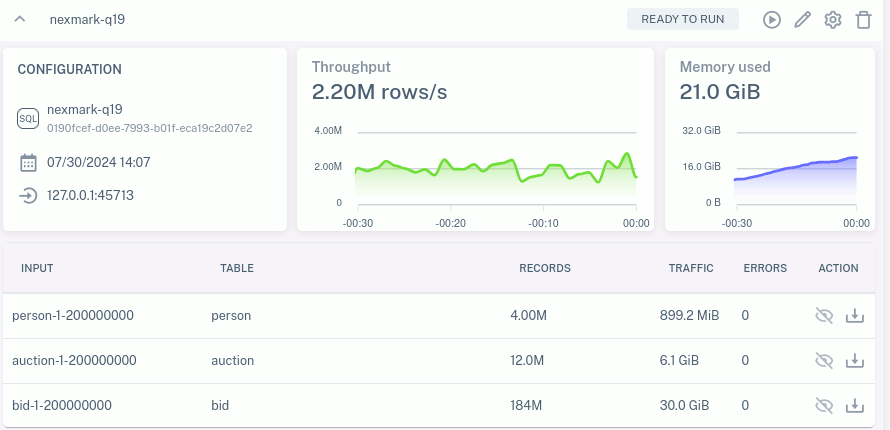
WHERE rank_number <= 10;Suppose we run this query in Feldera against 100,000,000 events of input data. On my test machine, a 64-core Threadripper 3990X with 256 GB RAM, running with 16 Feldera worker threads, it runs in about 61 s and uses about 51 GB RAM at peak. If I double the input to 200,000,000 events, it takes about 144 seconds and peaks at 111 GB of RAM. Whether 51 GB or 111 GB, that's a lot of memory to allocate:
| Input events | runtime | peak memory | |
| 100,000,000 | 61 s | 51 GB | |
| 200,000,000 | 144 s | 111 GB |
If we rerun the above test with storage enabled, memory usage drops greatly:
| input events | runtime | peak memory |
| 100,000,000 | 57 s | 23 GB |
| 200,000,000 | 166 s | 30 GB |
What this means for you is that a single node running Feldera can take you very, very far—beyond a million events per second at low cost! Stay tuned for more information and blog posts with more detailed information.


Other articles you may like

Database computations on Z-sets
How can Z-sets be used to implement database computations

Implementing Batch Processes with Feldera
Feldera turns time-consuming database batch jobs into fast incremental updates.

Feldera: three tools for the price of one
Feldera is not just a database engine. Feldera SQL is in some respects substantially more powerful than standard SQL, enabling new use cases.