
In previous blog posts we have described at a high level how the
Feldera incremental query engine works. An incremental query engine continuously evaluates a set of queries (in our system these queries are described as database views). The queries depend on some data sources that continuously change.
The Feldera query engine (named DBSP) receives as inputs the changes applied to the data sources, and produces as outputs the changes of the results of the queries. The query engine uses the same data structure to represent all changes; this representation is used for inputs, outputs, and the internal data structures. This representation is the Z-set, and its close relative, the Indexed Z-set.
A Z-set looks very much like a traditional database table, but it additionally has a weight attached to each row. A positive weight shows that a row is being added, while a negative weight shows that a row is being removed, as in this diagram:

This example Z-set, which could illustrate changes in a database of record artists, is adding two rows of "Miles, Davis", removing two rows of "Bruce, Springsteen", and removing one row of "Taylor, Swift".
Z-Sets as a data exchange mechanism
We believe that Z-Sets are a very simple and clean abstraction, and that they should be the standard data exchange tool between data-processing systems.
However, today very few data processing systems operate seamlessly with change data. Some systems accept negative changes as inputs, but almost no systems can express naturally negative changes as outputs. For example, in database systems the DELETE SQL statement represents a negative change to input tables.
There are many benefits for adopting Z-Sets as a universal data exchange mechanism:
- As we have shown, Z-Sets can represent traditional database tables, so any systems that need to exchange table data can encode this information in Z-sets.
- In many applications both input and output changes are much smaller than the actual objects being modified. Having the ability to only transmit changes between systems may significantly increase their efficiency.
- A database system accepts changes as inputs, but cannot produce directly changes as outputs. This makes the system difficult to interface with other databases. Witness how difficult it is to move data reliably and efficiently between database systems using Change Data-Capture (CDC) systems.
- Z-sets have some very nice mathematical properties. This means that a sequence of operations described as Z-sets can be combined in "batches", and yet the final result obtained by applying a query to the sequence of batches is always the same, no matter how the sequence is split into batches.
However, to represent a general notion of a change to a database, a Z-Set is not sufficient: a Z-set is a change applied to one table, but in general, we should be able to express changes applied to multiple tables atomically, in one indivisible step. A change is thus a list of Z-sets, one for each input table.
To and from Z-Sets
A system like Feldera's DBSP incremental query engine, which computes only on changes, has to be able to receive data from today's data sources, and to send data to the existing data consumers (sinks). This requires building connectors. There are input connectors, which essentially convert data from other systems into Z-sets, and output connectors, which convert Z-sets into representations that are suitable for other systems.
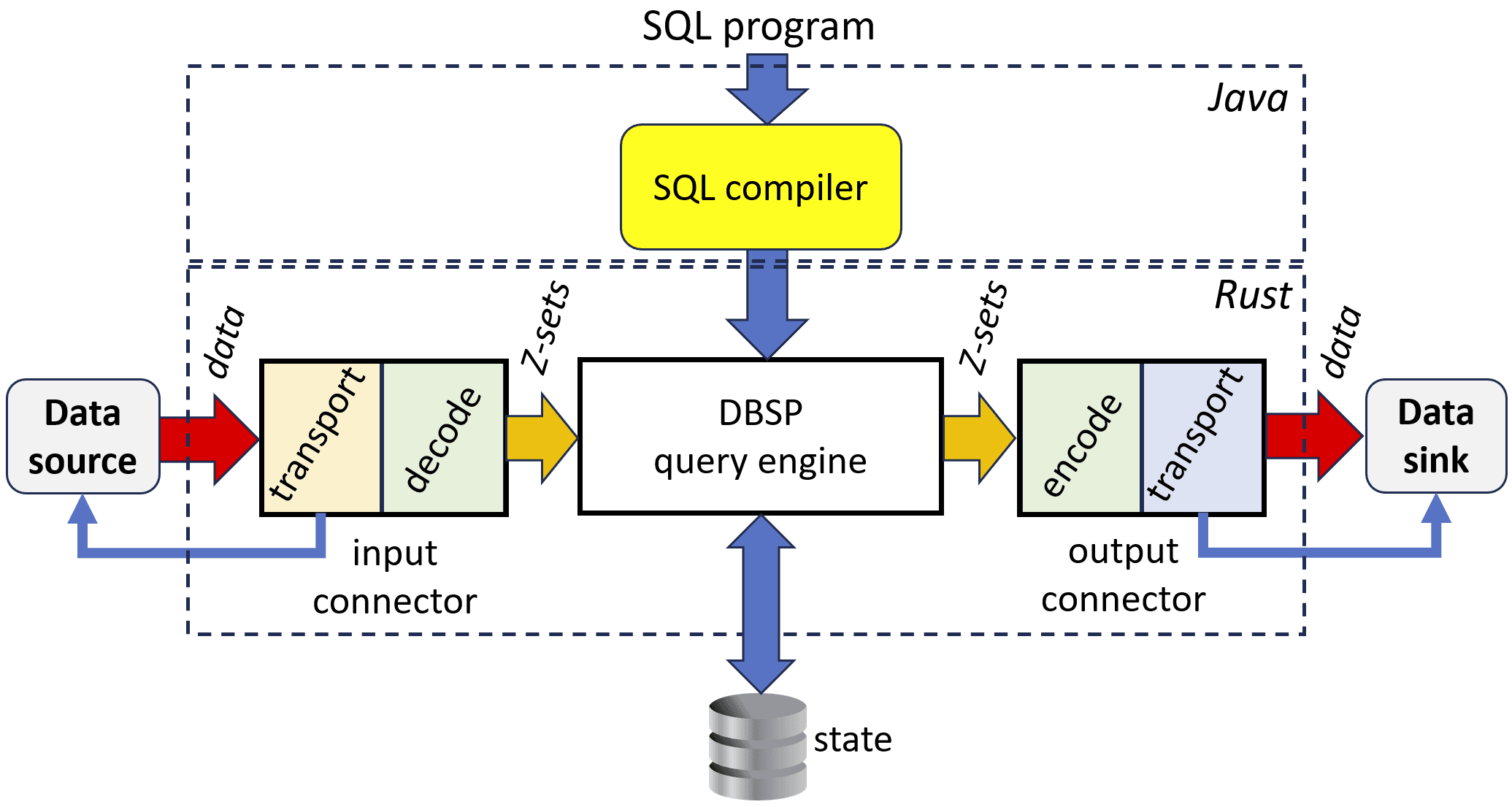
The following diagram is a (simplified) picture of the flow of data.

Each dotted box indicates logically a separate executable (although the bottom dotted box may in turn be executed in parallel on a distributed scale-out system; this is a topic that we'll address in a future blog post).
The SQL Compiler
The top dotted box is the SQL compiler. The compiler is written in Java, around the Apache Calcite framework, which was designed for building SQL compilers and optimizers.
The SQL compiler receives a description of the schema of the input tables (left blue arrow) and the code (queries) (top blue arrow), written as database views. The schema of the input tables can be optionally received from an external system, such as a traditional database, or a schema registry.
The SQL compiler produces as output a program written in Rust. That is the white box labeled "DBSP query engine." Feldera compiles the queries into Rust source code, then compiles the generated code using a Rust compiler, and then finally executes them. While the Rust compiler is on the slow side, since these queries are designed to run continuously for a long time, it pays off to optimize them heavily.
The connectors
The bottom dotted box is a process running a native executable, produced from Rust sources. While the "DBSP query engine" is generated by the compiler, the surrounding boxes are hand-written (also in Rust). For each kind of data source we have to implement an input connector, and for each kind of data sink we have to implement an output connector. In this figure we have shown only one input and only one output connector, but in general, the query engine can consume data from any number of sources (even thousands!), and each source can require a different kind of connector; similarly, a query can produce multiple views, and each view may be sending its changes towards a different kind of data sink, using a different kind of connector.
A connector has two tasks:
- coordinate with the data source/sink to send/receive the data in a timely and correct manner, using the protocols supported by the source/sink. This is the transport box. The red arrow shows data movement, while the thin blue arrow shows the additional control communication required for interacting with the data sources.
- convert the data from/to whatever format the data source/sink provides/accepts to/from the Z-set format used internally by the query engine. These are the encode and decode boxes.
Examples
Input connectors
- An input connector could be reading from a Kafka queue messages posted by a CDC data capture system powered by Debezium reading from a MySQL database. These messages are encoded in a JSON or Avro format (github).
The transport part of the connector is responsible for interacting with the Kafka input stream. The decoder converts JSON or Avro into Z-sets. - Another input connector could be reading data from a CSV file (github). The transport connector is responsible for reading the file data and splitting it into chunks of manageable size which are fed as individual Z-sets (all of them with positive changes).
- Yet another connector (github) could be listening for HTTP requests that POST a change encoded in JSON.
Output connectors
- An output connector could be using a JDBC connector powered by Debezium to write the change data into a Postgres database (github). The database can be consulted at any time to query the content of the corresponding views.
- Another output connector could be accumulating changes in a file in Parquet format, and periodically writing the file's content as a message into an output Kafka queue. (Under construction.)
Connector complexity
What makes these connectors hard to implement is the sheer diversity in the data types, data encodings, protocols, and capabilities of various data processing systems. To illustrate some problems:
- Some encodings, such as JSON, do not have native support for common database data types, such as DATEs. Many systems use different conventions for representing DATE data, e.g., strings "2020-02-02", numbers (of seconds since January 1, 1970).
- The same "datatype" may not have the same meaning between systems. For example, Postgres dates have a special value for of "Infinity" dates; some systems may limit TIME precision to millisecond, while other may allow nanoseconds, some may impose limits to the character set used, some systems may not support dates with time zones, etc.
- As we mentioned, some systems do not accept "negative" changes.
Such changes have to be encoded in a different form (e.g., add a column to the data with a "subtracted* boolean field), and then a separate computation must ingest such data into the destination tables.
- The source and target systems may be in different reliability zones, so the transport mechanism has to be able to tolerate interruptions and disconnections, and perhaps even resending change data that was sent already, but lost due to failures.
- Each system is tuned for a different operational regime: some systems perform best when inserting data in bulk (e.g., files, databases), other systems only accept changes at the level of individual events (e.g., Flink). The connector has to prepare the data in a suitable format for each destination.
Conclusions
In some respects building an incremental query engine is actually the easy part. The hard part is making it interact with a world which was not designed for incremental communication. We advocate for an approach where all data systems are designed from the ground up for exchanging change data. Until then, the complexity of the connectors will be necessary.




