
Recently, we added a custom storage engine to Feldera. Initially, we aimed to leverage an existing solution to avoid reinventing the wheel, and RocksDB seemed like a promising candidate. However, despite the apparent suitability, we encountered fundamental issues that led us to develop our own storage layer. In this blog post, we'll report these challenges and explain why they were so difficult to overcome.
State in Feldera
The initial implementation of Feldera kept all the data in memory. However, some data structures maintained by the streaming query engine may grow very large.
Feldera uses storage for two fundamental purposes:
- spilling large data structures that do not fit in memory to disk
- checkpointing internal state for fault tolerance or state migration
The data structure we use to index all our data is the Z-set: a collection of database rows with a (positive or negative) weight, sorted by a key. The main operations performed on Z-sets are:
- iterating over the set
- merging an existing (large) collection with a new (smaller) change
- lookup a (small) set of values in the collection by key
Why RocksDB seemed to be the right tool
Using RocksDB seemed to make sense due to its architectural similarities with how Feldera already managed state in-memory. Moreover, it is mature and widely-used software, powering systems including notable streaming platforms like Flink.
RocksDB is a generic key-value store that can represent multiple indexes using its column family feature, creating distinct namespaces for keys. It also offers all the APIs we needed: quick value retrieval for a given key and iteration over keys and values (both forwards and backwards) from a starting point (seek).
Both Feldera and RocksDB use a Log-structured merge-tree (LSM-Tree) as the underlying data-structure for managing insertions and deletions.
The mature RocksDB library for Rust provides all needed operations, including custom comparators for keys, zero-copy get operations, bulk inserts, and control over merging of entries with the same key during LSM compaction (which is inexpensive in Feldera -- it just consists of adding the weights).
Why RocksDB turned out to be a bad idea
Integrating RocksDB into Feldera was straightforward; we implemented the same API surface as our existing in-memory index data structure, the Spine.
Since RocksDB already had most of the required functionality, the commit that added the "Persistent Spine" was relatively small, around 3,000 lines of Rust code (with about one-third dedicated to tests).
Unfortunately, we quickly encountered several critical issues.
Lack of Scaling
Feldera pipelines can utilize multiple threads effectively because data is partitioned for processing, allowing the system to scale well across many CPUs with minimal shared state between threads. To avoid contention, we placed each persistent index in a separate column family when integrating RocksDB. However, we discovered that RocksDB doesn't scale well beyond a few threads. In fact, with RocksDB, our pipelines performed best when limited to a single thread.
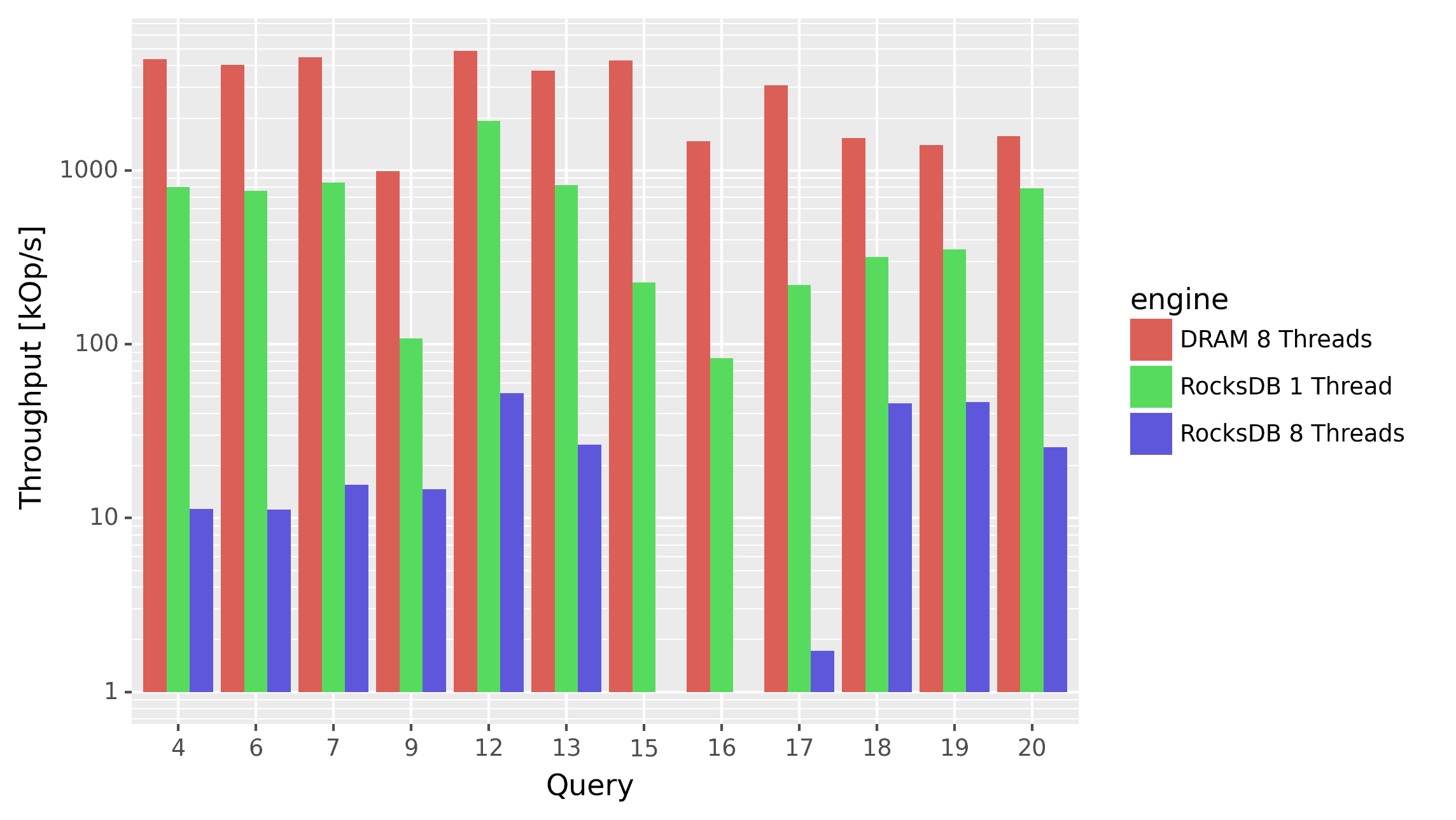
Here is a graph illustrating the severity of the issue (note the log-scale on the y-axis). It shows the performance for a subset of the nexmark queries that use indexes, comparing RocksDB with a single thread against RocksDB with eight threads. For reference, we also include the performance of Feldera configured to keep everything in DRAM data structures (which, as expected, performs much better).

RocksDB's single-threaded performance is quite good for a small dataset of around 3 million events (though it degrades with increasing dataset size). However, the real issue arises when scaling up to 8 threads. Performance drops dramatically for all queries, with throughput falling to just a few hundred events per second in the worst cases (Q15, Q16). This performance degradation is not due to limited hardware resources -- the underlying SSD usage remains minimal -- but rather due to software lock contention, presumably within the append log of RocksDB.
Unable to Leverage Zero-Copy Deserialization
Besides the scalability limitations, we also observed significant performance overheads even when running on a single thread. This was primarily due to the cost of deserializing keys and values from RocksDB, which stores data as slices of bytes (&[u8]), into the corresponding Rust types.
The performance profile below highlights the most resource-intensive functions while running nexmark queries. A substantial amount of time is now spent on key comparison (rocksdb_key_comparator, FindGreaterOrEqual, KeyComparator::operator) and memory allocation and deallocation (mi_malloc, mi_free) due to deserialization. In comparison, in the in-memory version of Feldera key comparison has a negligible overhead.

Retrieving keys and values from RocksDB requires deserializing them into Rust types. This process is slow because a custom comparison function is needed to match the ordering of in-memory types, instead of using RocksDB's default byte-wise comparison. For instance, seeking a key involves repeatedly deserializing keys until the correct one is found or confirmed to be absent. This is especially inefficient if the key is a string (or any other heap allocated object), as it involves memory allocation and immediate deallocation for each comparison.
One might argue that Rust has zero-copy deserialization libraries like rkyv that could be used together with RocksDB. Zero-copy deserialization allows directly casting the starting address of the bytes from RocksDB to an actual Rust type, eliminating CPU overhead.
However, zero-copy deserialization requires proper alignment of the deserialized bytes for the target Rust type. RocksDB operates on generic byte slices (&[u8]), which have an alignment requirement of 1 in Rust. Additionally, RocksDB is written in C++, which does not adhere to Rust's alignment rules. Attempting zero-copy deserialization with rkyv and RocksDB might occasionally work, but it often results in a panic due to misaligned slices:

Overwhelming Configuration Complexity
RocksDB offers an overwhelming number of configuration options, making it nearly impossible for non-experts to ensure optimal settings. The complexity is so significant that a HotStorage’24 paper detailed training a large language model (LLM) to identify good configurations. It won the best paper award at the conference.
Our attempts to tune RocksDB involved exploring numerous configurations, yet none resulted in substantial improvements in performance or scalability. The most notable adjustment was enabling BlobDB, which increased Feldera's end-to- end throughput by approximately 20%.
Slow Tests Due to Column Families
Our core engine includes a vast test-suite, where many tests use property-based testing and therefore run the same unit-test with thousands of different inputs to ensure correctness. When these tests required an index, RocksDB would quickly generate thousands of short-lived column families (one for each instantiated test). This caused our test suite to slow down significantly, extending the total run time from around 2 minutes to approximately 30 minutes. We traced this issue to a known performance degradation in RocksDB when creating many column families, a problem that has remained unresolved since 2019.
What's next?
Despite its initial promise, our journey with RocksDB highlighted several significant challenges. This led us to develop a custom storage engine for Feldera that better suits our specific requirements, offering improved performance and scalability. Our goal was to retain the strengths of RocksDB while addressing the issues highlighted in this post.
In upcoming blog posts, we will dive deeper into our custom storage engine. It features:
A Shared-Nothing Architecture: Unlike RocksDB's general-purpose design, our workload benefits from a partitioned approach. Each thread manages its own data, resulting in superior scalability.
Zero-Copy Deserialization: By leveraging the rkyv library and a custom file format, we have eliminated costly serialization and deserialization operations. This enables us to work directly (and safely) with persisted data, significantly boosting performance.
Type-Safe Optimizations: Our method allows for strong type constraints between serialized and deserialized data representation. We will explain how this paves the way for further neat performance improvements in our engine.




