
Users of Feldera, and many other systems, commonly read data from Kafka or compatible systems, such as Redpanda, over the Kafka protocol. Because Feldera is such a fast query engine, it's easy for data ingress to become the bottleneck. To help users and the Feldera input adapter for Kafka to achieve maximum performance, we invested some effort in experiments to figure out the best Kafka configuration and the best adapter design. This blog post reports our experiments and our recommendations.
Background
Kafka is a distributed system that stores and buffers messages, called “events”, which are stored on disk in numbered “partitions” within named “topics”. Kafka “producers” append events to partitions, and Kafka “consumers” read events from partitions. Feldera acts as a consumer when it reads input from Kafka (Feldera can also act as a producer by writing output to Kafka, but that is out of the scope of this blog post). See our previous blog post about seeking in Kafka for more detailed
background.
Consider a situation where a system produces n bytes of data into a Kafka topic by dividing it into k-byte events which it evenly spreads across p partitions. Even though a real system is unlikely to produce data in uniform sizes and perfectly even division, it is still useful for experiments. We are interested, in particular, in how the choices of n and p affect Kafka consumer performance.
For this blog, we only consider performance with a single broker, as one would typically use in test and development environments. We leave multiple-broker setups, as would typically be used in production environments, for future experiments.
Experiment Setup
To test Kafka performance, we wrote a program that produces data into Kafka topics with event size k and partition count p. We configured it to produce data into Kafka topics for each combination of k as 256 bytes, 512 bytes, 1 KiB, 4 KiB, 64 KiB, and 512 KiB, with p as either 1 or 16 partitions.
In particular, we reused our implementation of an event generator for the Nexmark benchmark. Since we're not running Nexmark itself, only using its input data, only the data distribution matters. We focused on the `bid` table, which holds 92% of Nexmark events and as produced by our generator contains records that range from 151 to 218 bytes long with an average of 172. We produced 10,000,000 Nexmark events and hence our tests read 9,200,000 bid records that comprise about 1.5 GiB of data.
We ran our experiments on a test machine using a 64-core, 128-thread AMD Ryzen 3990X Threadripper with 256 GB RAM, running Fedora Core 40. For our Kafka broker, we used Redpanda running on the same system using the official Docker image started with the command redpanda start --smp 2
We also tried redpanda start without any options, with --smp 16 to use 16 cores instead of just 2, or adding --mode dev-container. These different settings changed some of our measurements, but they did not change our recommendations. They also caused Redpanda to use more memory and CPU time.
Baselines
Once we generated data for each combination of k and p, we wanted
to figure out the fastest way for Feldera to read them. Before we
start, let's establish some baselines to act as guideposts.
Maximum performance baseline
For a maximum performance baseline, we also wrote the same data to a single text file and measured the time that it took wc -l to count the number of lines in the file (each record is one line). Because this reads directly from the kernel page cache, it should be faster than Kafka, which transmits data across a network connection. This took only 0.28 s on average.We can also measure a baseline cost of transmitting the data across process boundaries by introducing a pipe, e.g. cat | wc -l. This raised the time to 0.77 s on average.
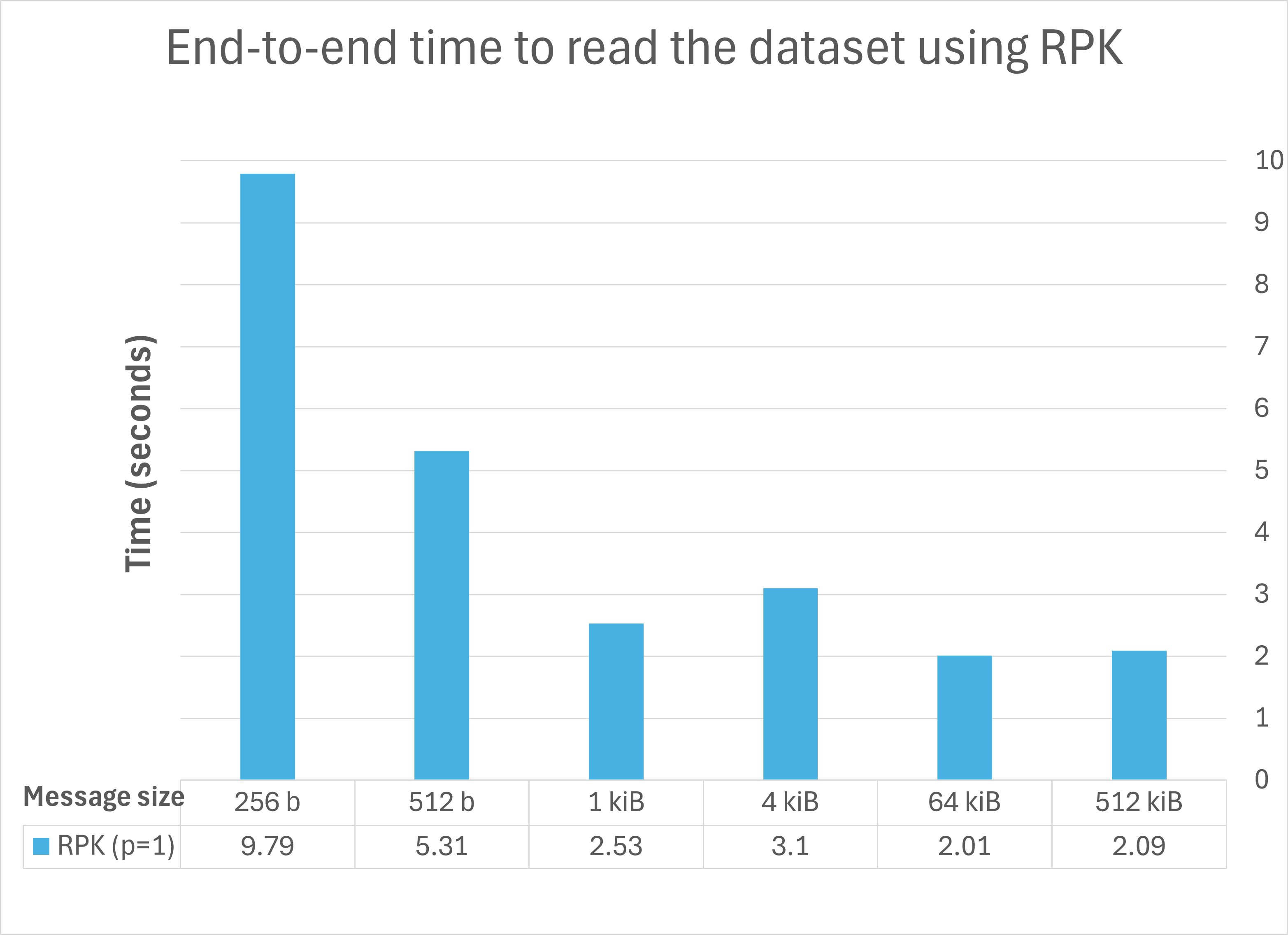
Kafka Protocol baseline
For a performance baseline over the Kafka protocol, we used Redpanda's rpk command-line utility. For p = 1, we measured the time to read the data from <topic> with a command like the following, where -f '' says to discard the data as it is read and -o :end says to read the topic from beginning to end and then exit:
time rpk topic consume -f '' -o :end <topic>We were unable to establish an rpk baseline for p = 16 because rpk does not provide a way to exit after reading all of the data in a multi-partition topic.
The results showed that the time to read a fixed amount of data from Kafka decreases as the event size increase, with decreasing returns between 4 KiB and 64 KiB:

Kafka in Rust performance
Feldera is written in Rust, so we wanted to measure the performance of Kafka consumers using the rdkafka Rust crate, which is a Rust wrapper around the librdkafka library that most Kafka language bindings use. We wrote a simple program that establishes a connection to a Kafka topic and reads all of the events from it in a loop. We obtained the following results for reading our data for each event size k and partition count p:

Comparing rpk (written in Go) to p = 1 for Rust, for large event sizes, the Rust crate performs better than rpk. As the message size shrinks, the Rust advantage also shrinks and then reverses; at the smallest message size, the Rust version takes about 3× the Go version. Go code is known for its "goroutines" that efficiently multiplex multiple tasks onto native threads, so one might speculate that the Go implementation uses these heavily and that, for large sizes, the additional overhead is a liability that decreases as the quantity of individual pieces of data to manage increases.
Comparing the Rust p = 1 and p = 16 results, we can see that multiple partitions are always a performance penalty, from 5% for the largest events to 40% for the smallest. However, our test consumer only uses a single thread. Let's try with multiple threads.
Per-thread partitions
The librdkafka library and the Rust crate based on it both support per-partition queues to a topic. Let's try breaking out each partition into a separate queue and a separate thread. We added a mode to our consumer test program to spawn a thread for each partition in the topic, assigning each one a queue for its own partition:

With 256-byte events (our smallest size), per-partition queues and threads are a big win for both 1 and 16 partitions. Otherwise, per-partition queues do make a difference but not in a consistent direction, e.g., for p = 16, at 4 KiB the per-partition queues exact a 2× penalty but at 1 KiB they yield a 31% improvement. (These numbers may look random, but they are reproducible across multiple runs.)
Thread-pool
librdkafka also supports reading from a topic from multiple threads without assigning particular partitions to threads. In this case, the library passes events to threads as they become available. We added another mode to our consumer test program that spawned a pool of threads that compete to read events. We measured the performance with 1, 2, 4, 8, and 16 threads in the pool. The best performance was with a 2-thread pool:

The thread pool results are slower than partition queue results in every case for a single partition. For 16 partitions, a thread pool is slightly slower for large events and slightly faster for small events.
Conclusions
Our experiment demonstrated that, generally speaking, for consuming a fixed amount of data from Redpanda with a single broker, the size of individual events is key to performance:
- Larger events (at least 1 KiB) yield better performance. For these events, threading the consumer typically hurts performance (by up to 69%). The performance value of multiple partitions is a toss-up: it generally had little effect but in some cases yielded from -30% to 200% improvement.
- Smaller events (less than 1 KiB) yield worse performance: 256-byte events read between 3× and 13× slower than 1-KiB events depending on partitioning and threading. For these events, threading the consumer generally improves performance, with the advantage growing as the events become smaller (becoming over 4× improvement for 256-byte events). Multiple partitions only hurt performance.
Thus, at least for development environments, one can conclude that, to improve performance:
- Configure a single partitition.
- Consolidate multiple records into fewer events.
- If, despite consolidation, events tend to be less than 1 KiB, use
multiple threads for consumption.
The following graph summarizes all of the previous ones:





