
We have recently announced support for ad-hoc queries in Feldera. In this blog post we describe how this feature is implemented.
Continuous query pipelines
Feldera enables users to build data pipelines that continuously evaluate queries over data streams by writing SQL programs. Data streams are modeled as database tables that keep changing (as they do in traditional databases). SQL programs are used to define views.
A SQL Compiler transforms the SQL program comprising table and view definitions into a streaming Rust program. The Rust program is in turn compiled into an executable. The executable is started (by a management process), connected to data sources and sinks, and then will continuously process data. This running process is called a pipeline.
For each set of changes to the inputs, the pipeline computes the changes required in the user-defined views and emits them as outputs. The main value proposition of Feldera is that it computes these changes incrementally, without running the SQL query over the full input tables. Feldera pipelines convert input changes into output changes.
Debugging continuous pipelines
This model is very efficient, but it differs significantly from the model of traditional databases. People have accumulated decades of experience and many useful tools for interacting with databases. How do I know whether the SQL program I wrote for a continuous pipeline does what I expect?
In addition to debugging pipelines, ad hoc queries are useful to inspect the current state. A user who hasn't observed all output changes does not know what's the current content of each table/view. Moreover, some users don't want or need to maintain an external database and would rather use Feldera.
The easiest way to help people troubleshoot continuous pipelines is to make them look as much as possible like traditional databases, enabling them to reuse many of the tools they are familiar with.
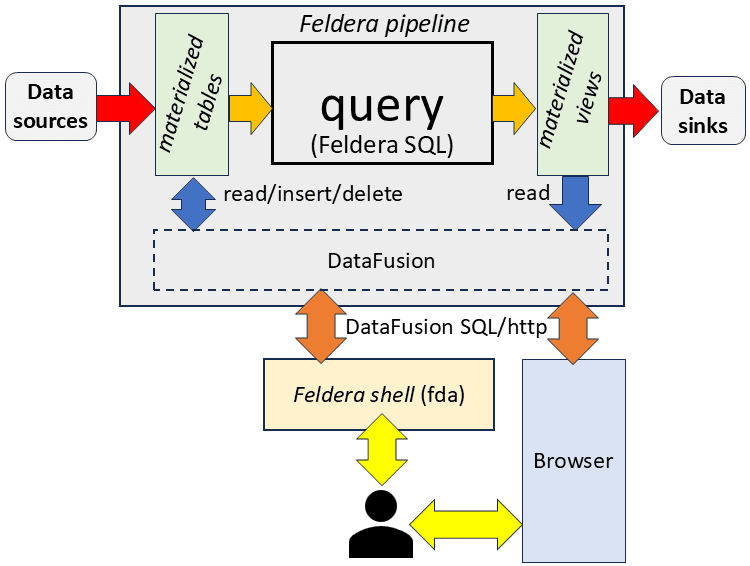
The first step is to convert the streams of changes to tables and views into more traditional database tables. This can be done in Feldera SQL by materializing the tables and views: https://docs.feldera.com/sql/materialized.
In a normal database tables are always materialized. After all, that is the point of the database: to keep the data. Feldera does just the opposite: it only keeps as much data as necessary to compute the views it maintains, but no more. If you want to ask Feldera to actually store the data in an input table you can use a table property, as in the following example:
CREATE TABLE T(...) WITH ('materialized' = 'true');
Databases do not always store the data in the views either, so for materializing views Feldera SQL uses the standard database syntax:
CREATE MATERIALIZED VIEW V AS SELECT ...;The way Feldera materializes both tables and views is the same: a table or a view is actually the accumulation (or integration) of all the changes since the pipeline was launched.
Querying materialized tables and views
What is the best way to inspect the contents of tables and views? Well, there is a programming language designed exactly for doing that, and it's called... SQL.
Ideally one would use the same SQL dialect for building the pipeline and for inspecting the data. The current design of Feldera is optimized for maximum performance. The high performance of Feldera pipelines is obtained by the compilation process described above, which transforms queries into executable programs. This trade-off is reasonable for the target use case, where pipelines are designed to run for long stretches of time, and thus it makes sense for them to be as efficient as possible.
The downside of this process is that the Rust compilation is slow. And this is a problem for developers, because it slows down the development cycle.
Most databases can start executing queries very quickly because the queries are not compiled, but interpreted. Building an interpreter is a significant undertaking. So we have decided to reuse a high-quality open-source SQL interpreter, which is available as part of the Apache DataFusion project.
The DataFusion query engine is written in Rust as well, which makes it fast, and safe. The DataFusion interpreter is linked within a Feldera pipeline. Some glue logic exposes the Feldera tables and views as DataFusion tables, allowing the DataFusion code to acces them directly.
DataFusion
The following diagram shows the flow of data:

The user can interact with the DataFusion interpreter using either the Feldera Shell or the web-based UI using a browser, the Python SDK, or even directly using the REST API. The web UI looks like this:

Modifying data
As an additional benefit of this approach, the user can also issue SQL commands to insert or modify the data in the tables. This is a great tool for debugging, and it allows users to test pipelines without connecting them to any data sources, using SQL INSERT commands. (In the future we may also support UPDATE and DELETE commands, but currently we do not.)
Shortcomings
As with everything else in life, there are trade-offs. While this approach allowed us to quickly offer a very useful capability for developers and testers, it comes with some downsides as well.
One problem is that the DataFusion queries execute in the same process with the pipeline, so they compete for resources. A complex query can slow down the main pipeline. This problem can be alleviated in the future by running the DataFusion in a separate process, using independent compute resources, and having the data be shared through a common storage layer.
A second problem is that no two SQL dialects are the same. There are minute differences between the capabilities of Apache DataFusion and Apache Calcite as SQL engines. (The Feldera Compiler is based on Calcite). This means that running the same query using the DataFusion engine on the input tables may provide a different result than using the query within the pipeline (for example, rounding may be different). Or there may be queries that one engine accepts, but the other one rejects.
Eventually we plan to resolve this discrepancy, but until then users will have to understand and live with this limitation.




