Fault tolerance technical details


Fault tolerance in Feldera means that if a pipeline compute node fails and restarts, then the pipeline resumes gracefully, without dropping or duplicating input or output. Previously, we showed how fault tolerance works from a user point of view. In this blog post, we delve into some of the technical details of fault tolerance.
Basics
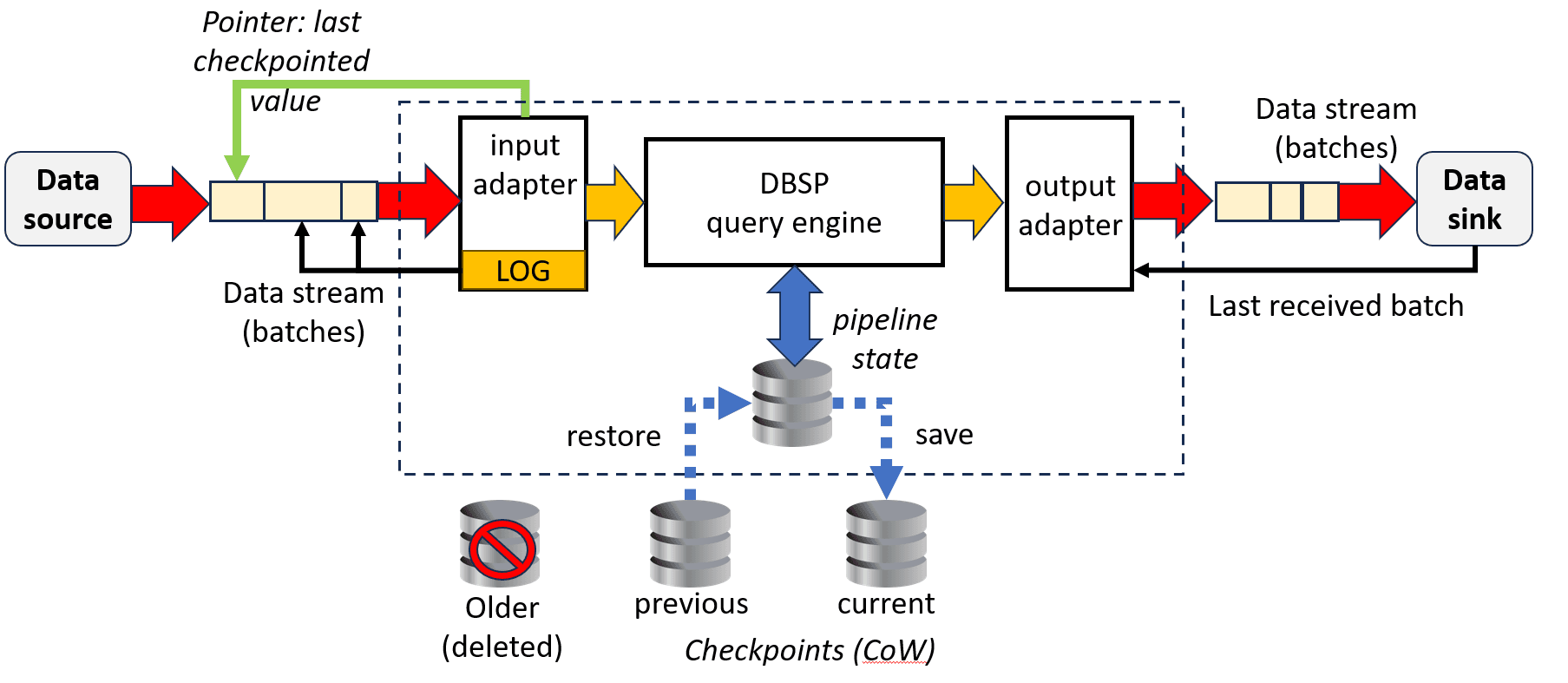
Feldera implements fault tolerance with checkpoints and a log. A checkpoint is a consistent snapshot of the Feldera system's state, including computation and the input and output adapters. Periodically (by default, every 60 seconds), Feldera writes a checkpoint to stable storage. The checkpoint is written incrementally, in that it can reuse any part of the previous checkpoint that has not changed. Data that was in the previous checkpoint, and is now unused, is freed.
Since failures can happen at any time, periodic checkpoints are insufficient to recover the state before the failure. This is where the log comes into play. For each batch of data that Feldera processes through the pipeline, it logs enough information to obtain another copy of the batch's input data later. If the compute node fails, then, to resume, Feldera reads the most recent checkpoint, then it fetches and replays each batch of input through the pipeline in the same order as it was done before. When a checkpoint is made, older log entries are no longer useful and are freed.
Example
Let’s consider a greatly simplified case for the purpose of illustration, in the form of a pipeline that accepts integers as input and outputs the running total. The following diagram shows one way this could work with fault tolerance enabled. The “input” row shows individual input values as they are received. Feldera feeds inputs through the pipeline in batches whose sizes may vary, and produces one output per batch shown in the “output’ row: for example, 5 + 7 is 12, the first output, and 12 + 3 is 15, the second output. The “log” records the locations of inputs, to allow the same inputs to be found and re-read in the future. Finally, “checkpoints” shows how Feldera can occasionally record the state of the pipeline: for example, to resume after a failure after checkpointing 47, Feldera only needs to replay input that arrived afterward, rather than all of the input from the start of the pipeline.

Input and Output Adapters
Fault tolerance requires Feldera to coordinate with the systems backing all of the input and output adapters. For input adapters, to recover from a crash, Feldera must be able to re-read the exact data input for each batch, so that it can replay it, and then resume reading the input just after the last replayed batch. Feldera uses a checksum included in the log to ensure that the data read for replay is the same as the original data.
The specifics of how data is re-read for replay and resume, and therefore what goes into the log, is the trickiest part of pipeline fault tolerance. This mechanism is specific to each kind of input adapter. The Kafka input adapter logs per-partition event offsets within each input topic, the HTTP GET input adapter logs byte offsets within a URL, and so on. There is no way to re-read data that arrives through the HTTP input connector or through ad-hoc queries, so in those cases, Feldera logs, and replays, all of the input data.
For output adapters, replay might cause Feldera to write the same output more than once to a given output adapter. For an adapter whose output is outside Feldera’s direct control, Feldera needs help from the output adapter’s target to solve this problem. Consider, for example, an output adapter that accesses a network service. Feldera sends a batch of output to the service and waits for a reply that confirms that it was received. If the Feldera pipeline fails without receiving confirmation, when it resumes later, only by querying the network service it can discover whether the output was received. Thus, each fault-tolerant Feldera output adapter needs to provide some support to enable once-only writes. The Kafka output adapter, for example, includes a sequence number in each output event, and on resume skips re-writing events whose sequence numbers are already present. (Some applications can tolerate duplicated output, so fault-tolerant Feldera pipelines are allowed to include non-fault-tolerant output adapters.)
In addition to input and output requirements, the replay process requires computation in a pipeline to be reproducible, meaning that, given the same input and the same pipeline state, the pipeline always produces the same output. The DBSP technology underpinning Feldera produces reproducible results for most database queries available through SQL. One exception is queries that use SQL’s NOW function, which returns the current time; this can be made reproducible by logging the time that was originally used and using that time in the replay. We also need to avoid other reasons that results can be non-reproducible, such as floating-point results that differ across processor architectures (by replaying on the same architecture) or across compiler optimizations (by using the same compiler and optimizations).
Rationale
We considered other ways to implement fault tolerance. One might ask, for example, why it’s necessary to replay exactly the same sequence of input batches. After all, all “normal” queries will ultimately produce the same results as long as the input is the same, ignoring how it is divided into input steps. Couldn’t Feldera just replay starting from a checkpoint, without regard for division of input into batches? But this ignores LATENESS, a SQL extension implemented by Feldera: a table or view annotated with LATENESS might have different contents if data is split into input batches in different ways. Such a solution would also require Feldera to re-read output beyond the most recent checkpoint and compare it against the replayed output, which not all output connectors can gracefully support. It would defeat Feldera’s synchronous streaming guarantee, which says that Feldera produces exactly one output change for each input change; instead, when it crashes, Feldera could make some output changes come from multiple input changes or split a single input change across multiple output changes, or a combination.
Another reasonable question is why Feldera has both checkpoints and logging. Why not simply checkpoint after processing each batch of data through the pipeline? This would indeed work, but it would be slower than the approach we adopted, because checkpoints, and even the incremental changes to them for a single pipeline step, are normally bigger than a log record. In turn, that’s because input log records usually just say where to obtain the data for a step, but checkpoints contain records themselves, or at least summaries detailed enough to carry on further computations for the pipelines. In addition, any but the simplest SQL programs produce several of these summaries.
We considered many other factors in the design of the Feldera approach to fault tolerance. If you are interested in more of the details, take a look at our dist-design repository on GitHub and its history and issue tracker, which records the discussions we conducted and still lists many of the candidate approaches and their trade-offs.



