Fault tolerance is now in preview for our enterprise offering!
As a user, this means you can run Feldera pipelines on network-attached or remote storage, but then crash or completely take out the underlying VM or physical machine, and the pipeline will simply be rescheduled on a separate machine and pick up from exactly where it left off.
This means you can run pipelines, scale your cluster up-and-down, or even completely take out all machines, and as long as the remote storage is available, the pipeline can simply pick up from where it left off once rescheduled. That's useful, for example, for adding or removing capacity in a pool of machines.
Let's see this feature in action. We'll use the following SQL program that simulates a simple set of bank balances. We use the datagen connector to automatically generate 100,000,000 transactions. Because we specify a particular random seed, the generated data is the same in every run:
CREATE TABLE transactions (
from_account INT NOT NULL,
to_account INT NOT NULL,
amount INT NOT NULL,
ts TIMESTAMP NOT NULL
) WITH ('connectors' = '[{
"transport": {
"name": "datagen", "config": {
"seed": 0,
"plan": [{
"limit": 100000000,
"fields": {
"from_account": { "strategy": "uniform", "range": [1,10] },
"to_account": { "strategy": "uniform", "range": [1,10] },
"amount": { "strategy": "zipf", "range": [1,1000] },
"ts": { "scale": 1000 }
}
}]
}
}
}]');
CREATE VIEW credits AS
SELECT
to_account AS account,
sum(amount) AS credits
FROM
transactions
GROUP BY
to_account;
CREATE VIEW debits AS
SELECT
from_account AS account,
sum(amount) AS debits
FROM
transactions
GROUP BY
from_account;
CREATE MATERIALIZED VIEW balance AS
SELECT
credits.account AS account,
credits - debits AS balance
FROM
credits,
debits
WHERE
credits.account = debits.account;
First, let's run our pipeline without fault tolerance. This takes a couple of minutes, so here it is sped up to make it easier to watch:

We can use an ad-hoc query to see the end result of the computation:

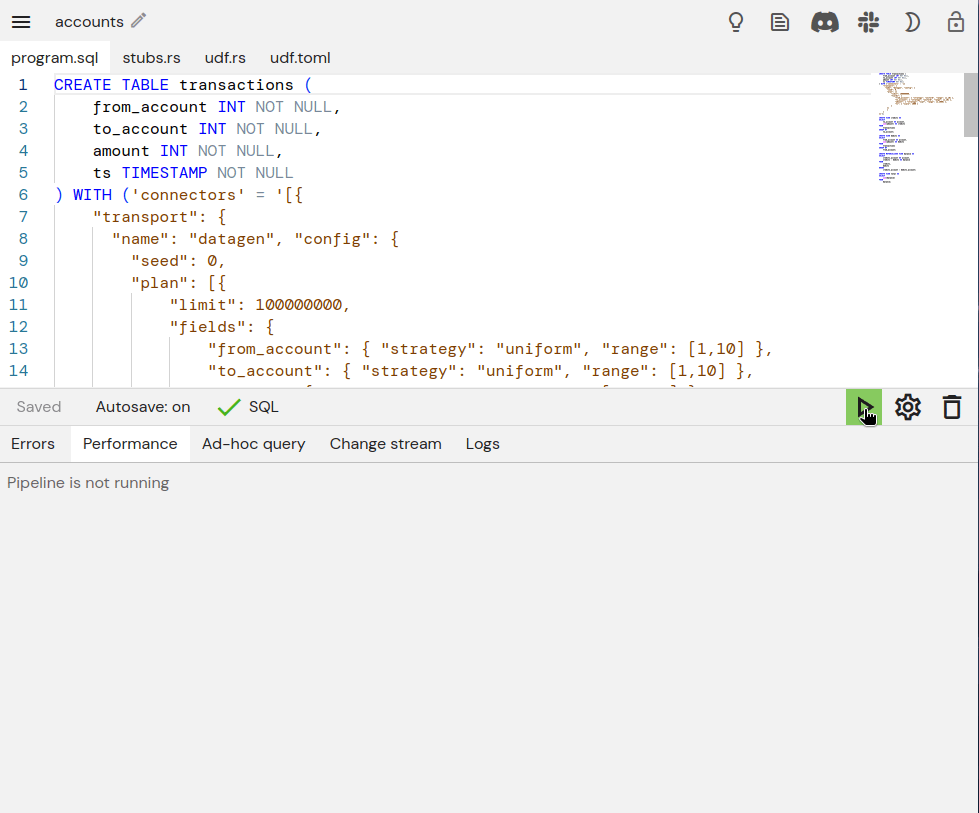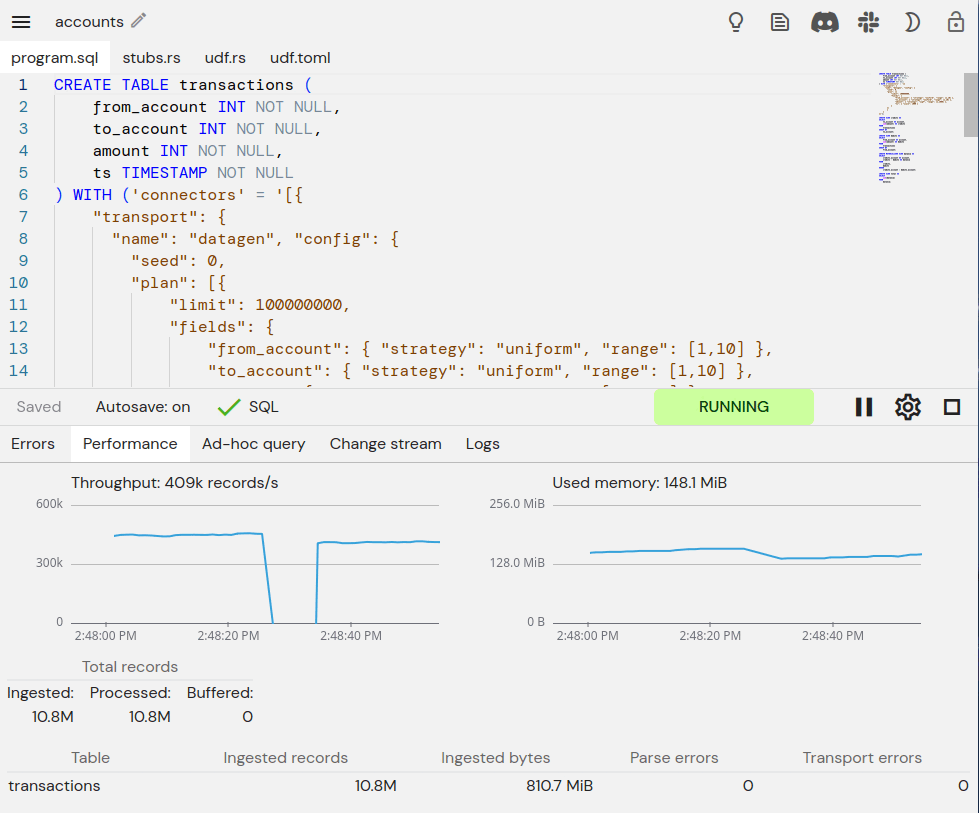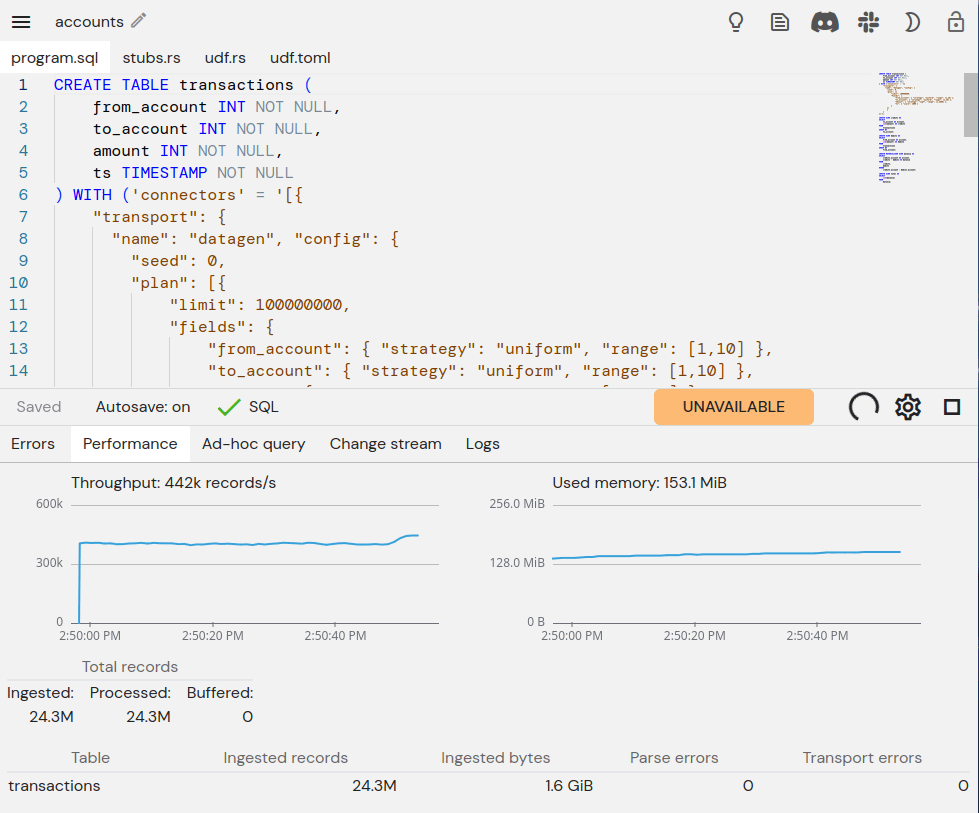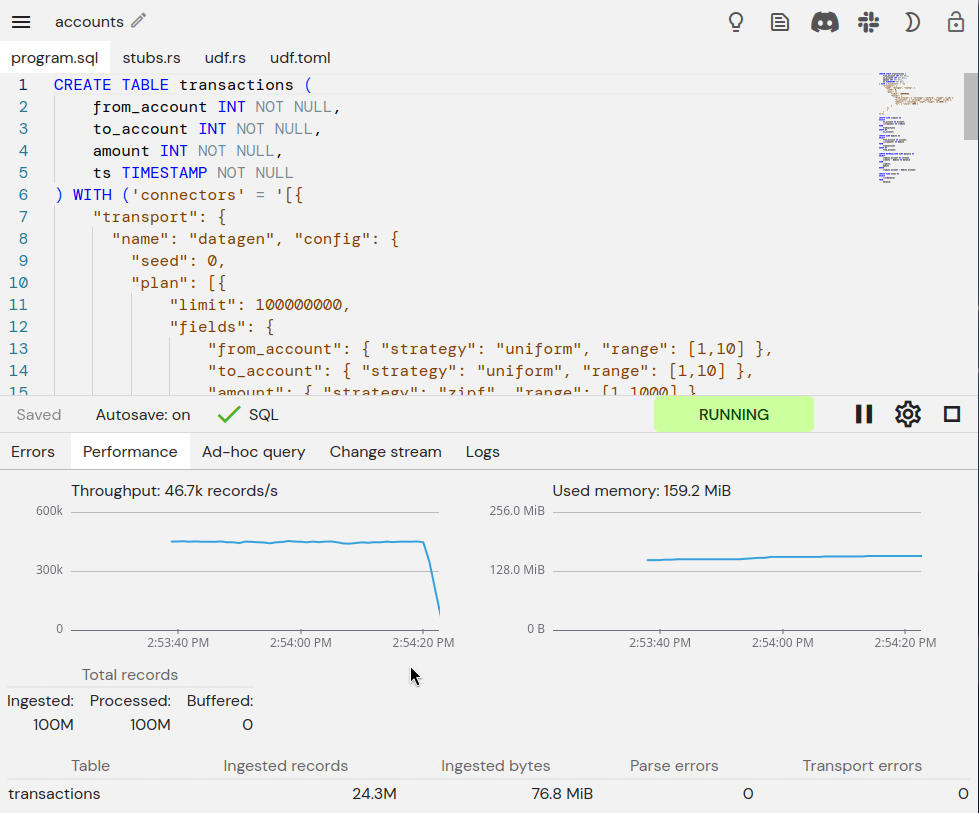
Now, enable storage and fault tolerance for the pipeline:

We can run the same pipeline again and, while it's running, delete the pod (using kubectl from a terminal). Each time, the pipeline transitions from RUNNING to UNAVAILABLE for a few seconds before Kubernetes starts a new pod. We see a corresponding dip in the throughput graph while the new pod starts and resumes the computation:

Finally, after the computation completes, we run the same ad-hoc query as before. The results are the same as when there were no failures, which demonstrates that fault tolerance was successful!





