
The As-Of Join Operator
- What was the stock price at the exact moment of the transaction❓
- How far was the credit card swiped from the last known user's location at the time of purchase❓
- What was the account balance just before the money transfer❓
These types of queries are common in time series analytics problems, such as real-time fraud detection. Such queries can be expressed in SQL using a specialized form of the join operator, the as-of join. While not part of ANSI SQL, as-of join is supported by many modern databases and data warehouses, including Snowflake and DuckDB.
We have recently introduced support for as-of join to Feldera. Like everything else in Feldera, the `ASOF JOIN` operator
- is fully incremental
- runs at the rate of millions of records per second
- produces perfectly accurate results even when inputs arrive out of order.
Let's see how you can use this operator in your fraud detection pipeline.
Where was Waldo?
Any real-time fraud detection pipeline ingests raw events, e.g., payments or credit card transactions. The first thing we want to do with these events is to locate the associated customer record for each event, so we can use customer info to flag suspicious transactions. This is known as data enrichment, since we are enriching raw event data with customer attributes. In SQL, data enrichment can be directly expressed using ASOF JOIN. Here is an example:
CREATE TABLE transaction (
customer_id BIGINT NOT NULL,
amt DOUBLE,
state VARCHAR,
ts TIMESTAMP LATENESS INTERVAL 1 DAYS
);
CREATE TABLE customer (
id BIGINT NOT NULL,
name varchar,
state VARCHAR,
ts TIMESTAMP LATENESS INTERVAL 7 DAYS
);
-- Find the customer record for each transaction, flag the transaction as
-- out-of-state if the state where the transaction was performed doesn't
-- match customer's home state.
CREATE MATERIALIZED VIEW enriched_transaction AS
SELECT
transaction.*,
transaction.state != customer.state AS out_of_state
FROM
transaction LEFT ASOF JOIN customer
MATCH_CONDITION ( transaction.ts >= customer.ts )
ON transaction.customer_id = customer.id;
Let's break this down:
- Program inputs are modeled as two tables:
transactionandcustomer. - Both tables have timestamp columns:
- transactions are labeled with the time when the transaction took place
- customer records are labeled with the time when the record became effective
- Note an important modeling choice: when we get an updated customer record, we do not delete the old record, instead we add the new record with the timestamp set to the time when the update became effective.
- We use the
ASOF JOINoperator to match each transaction with the customer record effective at the time of the transaction:ON transaction.customer_id = customer.id- similar to the regular join, theONclause specifies columns used to find matching rows in the two tables- transaction
LEFT ASOF JOIN customer- theLEFTkeyword indicates that the join will includeNULLvalues for columns from the right table when no match is found. MATCH_CONDITION ( transaction.ts >= customer.ts )- specifies timestamp columns. The operator will return a matching customer record with the largest timestamp that does not exceed the transaction timestamp.
- Finally we combine transaction and customer columns to flag out-of-state transactions, where the state where the transaction was performed doesn't match customer's home state.
Time to see the as-of join in action. Create a new pipeline called asof in the Feldera sandbox and paste the SQL code shown above to it. Connect to the pipeline using the Feldera CLI:
# Make sure the $FELDERA_API_KEY env variable contains a valid Feldera API key.
> fda shell --host https://try.feldera.com asof
fda shell (0.26.0). Type "help" for help. Use Ctrl-D (i.e. EOF) to exit.
try.feldera.com/asof> restart
Pipeline shutdown successful.
Pipeline started successfully.
try.feldera.com/asof>We create a new customer record for a user named Waldo who lives in California. Waldo has made several recent purchases in California:
localhost:8080/asof> insert into customer values(100001, 'Waldo', 'CA', '2023-03-25T00:00:00');
+-------+
| count |
+-------+
| 1 |
+-------+
localhost:8080/asof> insert into transaction values
(100001, 125.00, 'CA', '2024-09-15T09:00:00'),
(100001, 13.99, 'CA', '2024-09-21T17:30:00'),
(100001, 65.99, 'CA', '2024-09-25T21:05:00');
+-------+
| count |
+-------+
| 3 |
+-------+
Then, on October 1 and 2, two transactions were made with Waldo's credit card in New Jersey. These transactions are correctly labeled as out-of-state:
localhost:8080/asof> insert into transaction values
(100001, 43.05, 'NJ', '2024-10-01T13:00:00'),
(100001, 100.00, 'NJ', '2024-10-02T05:30:00');
+-------+
| count |
+-------+
| 2 |
+-------+
localhost:8080/asof> select * from enriched_transaction where customer_id = 100001 ORDER BY ts;
+-------------+-------+-------+---------------------+--------------+
| customer_id | amt | state | ts | out_of_state |
+-------------+-------+-------+---------------------+--------------+
| 100001 | 125.0 | CA | 2024-09-15T09:00:00 | false |
| 100001 | 13.99 | CA | 2024-09-21T17:30:00 | false |
| 100001 | 65.99 | CA | 2024-09-25T21:05:00 | false |
| 100001 | 43.05 | NJ | 2024-10-01T13:00:00 | true |
| 100001 | 100.0 | NJ | 2024-10-02T05:30:00 | true |
+-------------+-------+-------+---------------------+--------------+
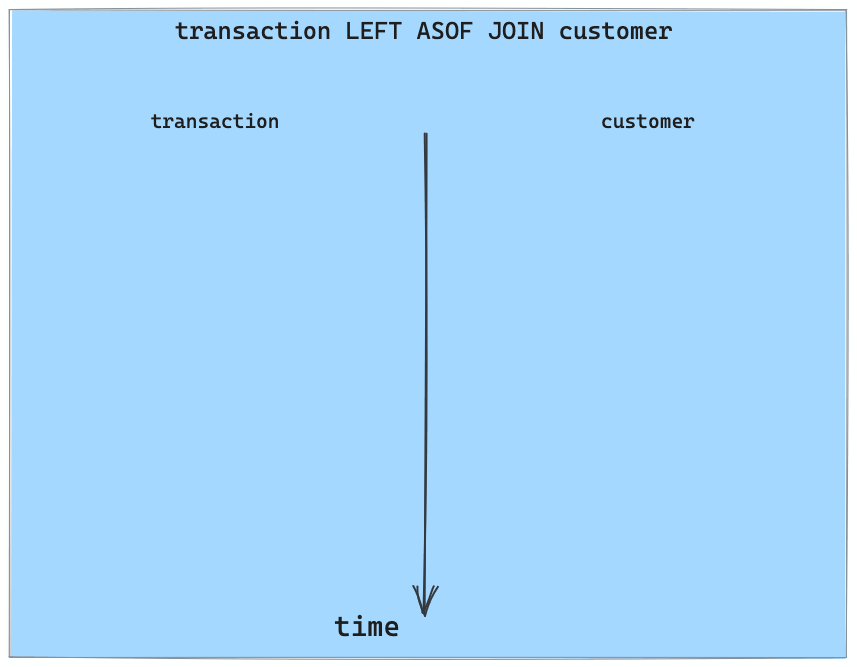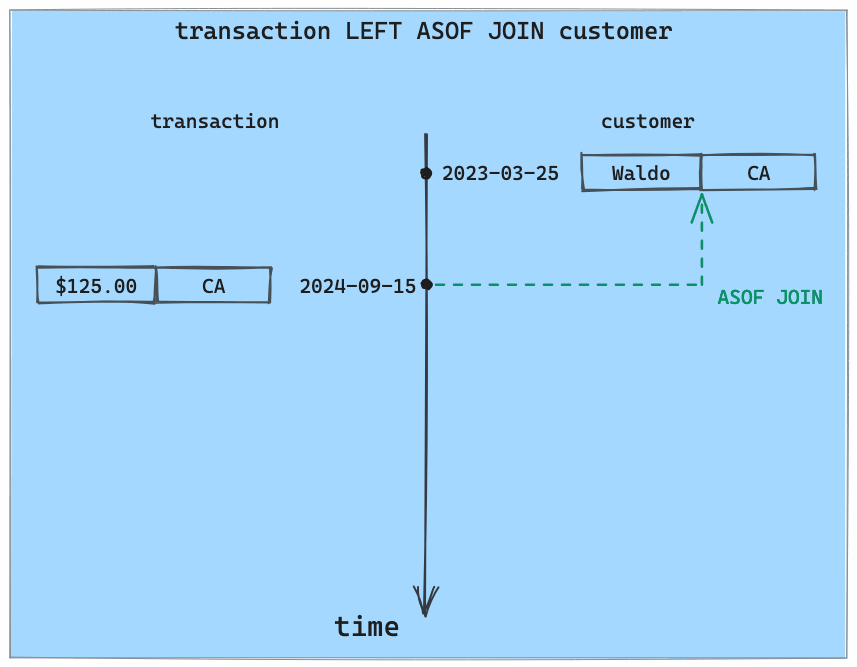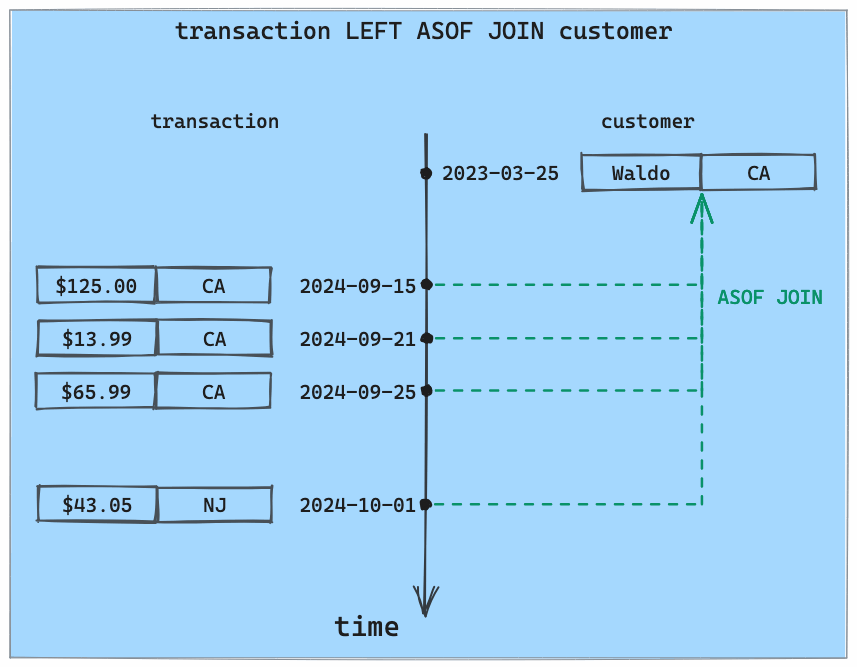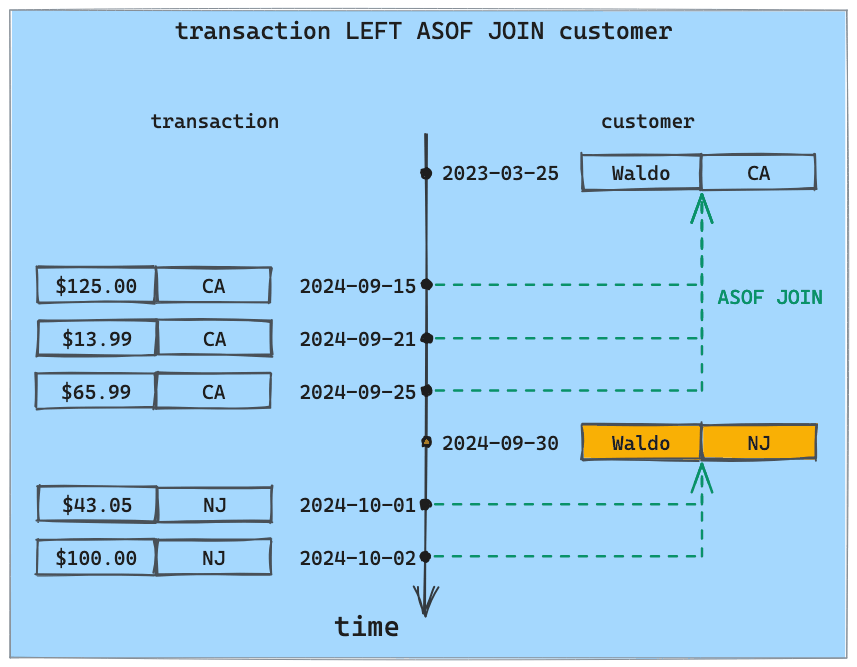
While investigating the transactions, the bank has established that Waldo indeed traveled to New Jersey on September 30:
localhost:8080/asof> insert into customer values(100001, 'Waldo', 'NJ', '2024-09-30T00:00:00');
Upon receiving this new input, the asof-join retroactively updates the status of the New Jersey transactions, which are no longer flagged as out-of-state:
localhost:8080/asof> select * from enriched_transaction where customer_id = 100001 ORDER BY ts;
+-------------+-------+-------+---------------------+--------------+
| customer_id | amt | state | ts | out_of_state |
+-------------+-------+-------+---------------------+--------------+
| 100001 | 125.0 | CA | 2024-09-15T09:00:00 | false |
| 100001 | 13.99 | CA | 2024-09-21T17:30:00 | false |
| 100001 | 65.99 | CA | 2024-09-25T21:05:00 | false |
| 100001 | 43.05 | NJ | 2024-10-01T13:00:00 | false |
| 100001 | 100.0 | NJ | 2024-10-02T05:30:00 | false |
+-------------+-------+-------+---------------------+--------------+
Note that the California transactions remain labeled as in-state since the most recent customer record for Waldo at the time the transactions were made is still the one with the California address.
Here is a visualization of this behavior.

Initially, all Waldo's transactions are matched to the first customer record that places Waldo in California. When the ['Waldo', 'NJ'] record is added with the 2024-09-30 timestamp, transactions that happened after this date (and only those transactions!) are retroactively matched to this new record.
As-of join vs regular join
Do we really need a fancy new join operator? Could we use the good old left join to do the job? Here is the same program using the left join:
CREATE TABLE customer (
id BIGINT NOT NULL PRIMARY KEY,
name varchar,
state VARCHAR,
ts TIMESTAMP LATENESS INTERVAL 7 DAYS
);
CREATE TABLE transaction (
customer_id BIGINT NOT NULL,
amt DOUBLE,
state VARCHAR,
ts TIMESTAMP LATENESS INTERVAL 1 DAYS
);
CREATE MATERIALIZED VIEW enriched_transaction AS
SELECT
transaction.*,
transaction.state != customer.state AS out_of_state
FROM
transaction LEFT JOIN customer
ON transaction.customer_id = customer.id;
And the same inputs:
localhost:8080/join> insert into customer values(100001, 'Waldo', 'CA', '2023-03-25T00:00:00');
+-------+
| count |
+-------+
| 1 |
+-------+
localhost:8080/join> insert into transaction values
(100001, 125.00, 'CA', '2024-09-15T09:00:00'),
(100001, 13.99, 'CA', '2024-09-21T17:30:00'),
(100001, 65.99, 'CA', '2024-09-25T21:05:00');
+-------+
| count |
+-------+
| 3 |
+-------+
localhost:8080/join> insert into transaction values
(100001, 43.05, 'NJ', '2024-10-01T13:00:00'),
(100001, 100.00, 'NJ', '2024-10-02T05:30:00');
+-------+
| count |
+-------+
| 2 |
+-------+
localhost:8080/join> insert into customer values(100001, 'Waldo', 'NJ', '2024-09-30T00:00:00');
+-------+
| count |
+-------+
| 1 |
+-------+
localhost:8080/join> select * from enriched_transaction where customer_id = 100001 ORDER BY ts;
+-------------+-------+-------+---------------------+--------------+
| customer_id | amt | state | ts | out_of_state |
+-------------+-------+-------+---------------------+--------------+
| 100001 | 125.0 | CA | 2024-09-15T09:00:00 | true |
| 100001 | 13.99 | CA | 2024-09-21T17:30:00 | true |
| 100001 | 65.99 | CA | 2024-09-25T21:05:00 | true |
| 100001 | 43.05 | NJ | 2024-10-01T13:00:00 | false |
| 100001 | 100.0 | NJ | 2024-10-02T05:30:00 | false |
+-------------+-------+-------+---------------------+--------------+
The join operator is not sensitive to the relative timing of events and ends up labeling California transactions as out-of-state, even though Waldo was still in California at the time.
The second problem is more subtle: since a customer record can change at any time, the join operator must store the entire transaction history in order to correctly update the output, thus its storage footprint will keep growing over time. The as-of join, on the other hand, can discard old transactions once it knows the final value of the customer record at the time of the transaction. This is what the LATENESS annotations in the table declarations are for. We leave a detailed discussion of lateness to a different blog series.
Performance
Let's rev up the Feldera engine and process some high-volume data using as-of join. I wrote a modified version of our example program that includes a random data generator that synthesizes 1 billion transactions and 1 million customer record updates at the rate of 3 million transactions and 3000 customer records per second.
CREATE TYPE transaction_struct AS (
customer_id BIGINT NOT NULL,
amt DOUBLE,
state VARCHAR,
ts TIMESTAMP
);
-- This table is used to generate semi-realistic synthetic data.
-- Each generated row contains a single customer record and 1000
-- transaction records.
--
-- The datagen is configured to generate 2000 such rows, i.e., 2 million transactions
-- per second.
CREATE TABLE input (
customer_id BIGINT NOT NULL,
name VARCHAR,
state VARCHAR,
ts TIMESTAMP LATENESS INTERVAL 7 days,
transactions transaction_struct ARRAY
) WITH (
-- 'materialized' = 'true',
'connectors' = '[{
"max_batch_size": 100,
"transport": {
"name": "datagen",
"config": {
"workers": 4,
"plan": [{
"limit": 1000000,
"rate": 3000,
"fields": {
"customer_id": { "range": [ 1, 10000 ] },
"name": { "strategy": "name" },
"state": {"strategy": "state_abbr"},
"ts": { "range": ["2023-01-01T00:00:00Z", "2030-08-18T00:00:00Z"], "scale": 100000 },
"transactions": {
"range": [1000, 1001],
"value": {
"fields": {
"customer_id": { "strategy": "zipf", "range": [ 1, 10000 ] },
"amt": { "strategy": "zipf", "range": [ 1, 10000 ] },
"state": {"strategy": "state_abbr"},
"ts": { "range": ["2023-01-01T00:00:00Z", "2030-12-31T00:00:00Z"], "scale": 100000 }
}
}
}
}
}]
}
}
}]'
);
-- Flatten the input table into separate `customer` and `transaction` views.
CREATE VIEW customer AS
SELECT
customer_id as id,
name,
state,
ts
FROM
input;
CREATE VIEW transaction AS
SELECT
tx.customer_id,
tx.amt,
tx.state,
tx.ts
FROM
input, unnest(transactions) as tx;
LATENESS transaction.ts INTERVAL 7 days;
CREATE VIEW enriched_transaction AS
SELECT
transaction.*,
transaction.state != customer.state AS out_of_state
FROM
transaction LEFT ASOF JOIN customer
MATCH_CONDITION ( transaction.ts >= customer.ts )
ON transaction.customer_id = customer.id;
I ran it on an M3 Pro MacBook with 14 cores. Feldera generated, ingested, and processed 1 billion events in 380 seconds with P99 latency of 45ms.
| Metric | Value |
| Total transactions | 1,000,000,000 |
| Throughput | 2.6M transactions/s |
| Memory | 4GiB |
| P99 Latency | 45ms |
Let's put this P99 latency into perspective. It means that within 45ms after receiving new input, Feldera has updated all views that depend on it. Remember, Feldera ensures strong consistency, i.e., the outputs it produces at any point in time are exactly what you'd get if you ran the same queries on the same inputs in batch mode with a traditional SQL database.
However, the conventional database would take orders of magnitude longer to compute the same queries over a dataset with 1 billion records. This is because it processes the entire dataset from scratch each time, whereas Feldera evaluates queries incrementally by performing work proportional to the size of new data, not the entire dataset.
Takeaways
Along with rolling aggregates, as-of joins are one of the essential tools for real-time feature engineering and time series analytics. Feldera provides a high-performance, fully incremental implementation of this operator, enabling:
- Online/offline consistency: incremental outputs computed on real-time data are identical to those you'd get from running the same queries in batch mode.
- Perfect feature freshness: Feldera updates its output views within milliseconds of receiving new inputs, allowing you to instantly serve the most up-to-date feature vectors to your ML model.
- High throughput: Even if you're not processing millions of events per second in real-time, Feldera's ability to support this level of throughput is crucial for offline training and backfilling, where you need to efficiently compute features over large historical datasets.
By combining these capabilities, Feldera enables you to build complex real-time feature engineering pipelines for fraud detection and other critical applications at scale, with precision and speed.
-----
In the next blog of the feature engineering series, we will compare and contrast two alternative approaches to real-time feature engineering: one using a general-purpose language like SQL, and the other leveraging domain-specific languages (DSLs).




